First comes medadata, then comes content. How to control your CCMS with metadata
Corresponding services: Metadata models for smart technical communication and Content component management systems
Metadata has led to a paradigm shift in technical communication. Component content management systems (CCMS) are no longer at the start of all processes. That role has shifted to metadata.
This article is based on a presentation by Ulrike Parson and Dr Achim Steinacker at tcworld conference 2021.
Current processes in technical writing
Many technical communicators work with a CCMS in which they edit content and review, translate, and release it with the aid of workflows. If the CCMS has suitable interfaces, the documentation team can also use information from external systems such as product information management or parts management.
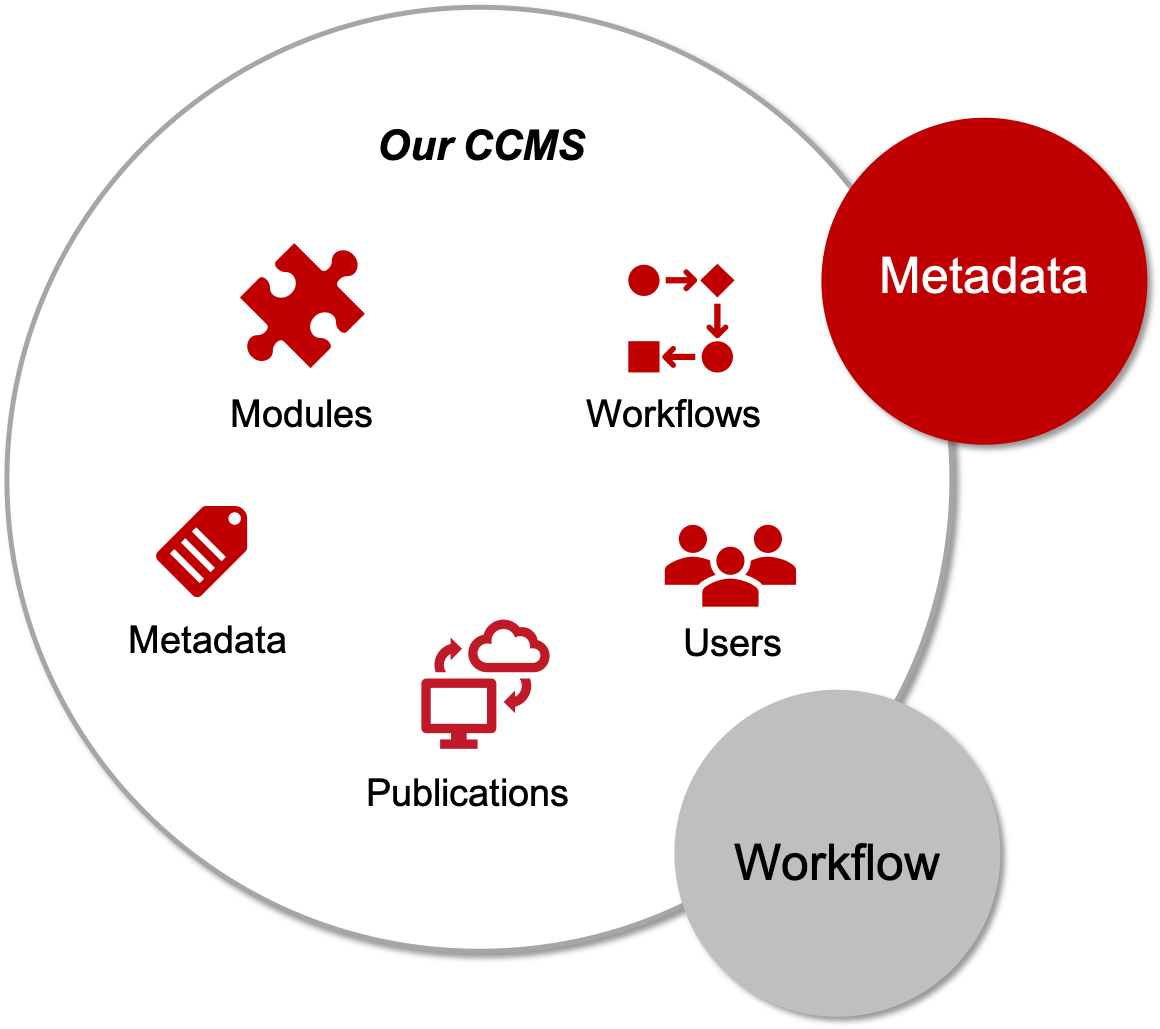
The CCMS stores both content and metadata. Metadata may be assigned by technical communicators or set automatically by the system. The documentation team works primarily with metadata for variant management to generate documentation for different product variants, platforms, target groups and media from one source. The team also handles administrative metadata linked to workflows, such as the creation date, release date, translation status, validity, and author.

Therefore, the traditional documentation and translation workflow can be basically broken down into three phases:
- Creating and editing content
- Translating content
- Publishing documents
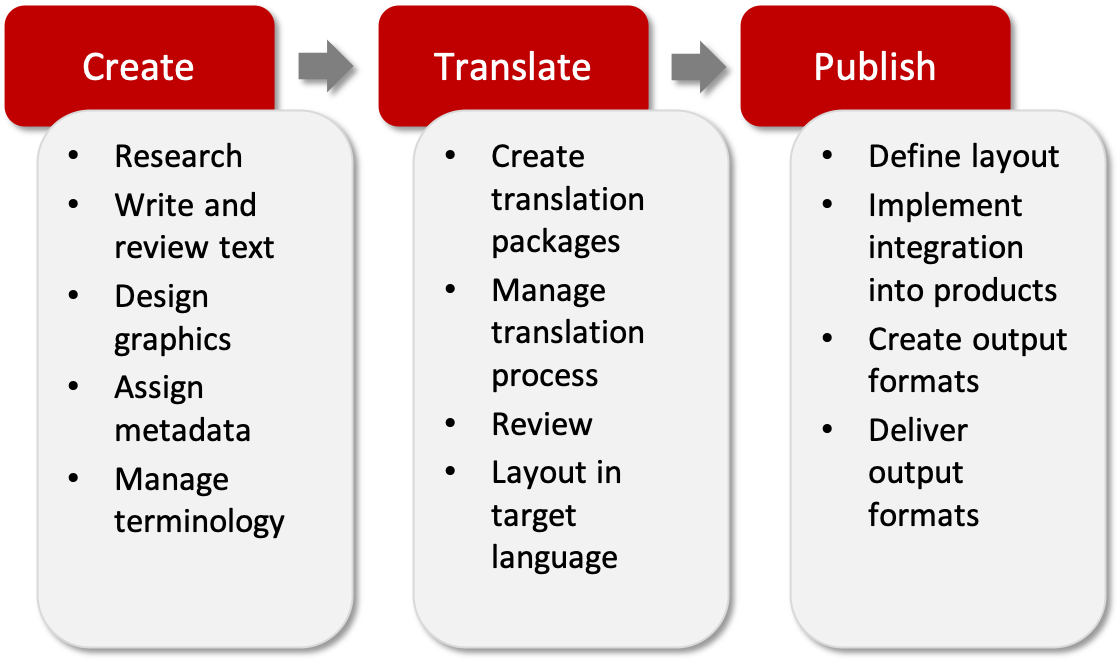
The published documents are delivered to different channels: as context-sensitive help to software products, as PDF documents to websites, or as iiRDS packages to content delivery portals, for example.
New requirements as a result of digitalization
Increasing digitalization creates new usage scenarios for information where content from technical documentation also plays a role.
Scenario 1: chatbots
Chatbots or voice assistants are becoming increasingly important. Users want to ask questions and quickly find a suitable solution to their problem. Chatbots are specialized in helping with specific questions and providing instructions for taking action.
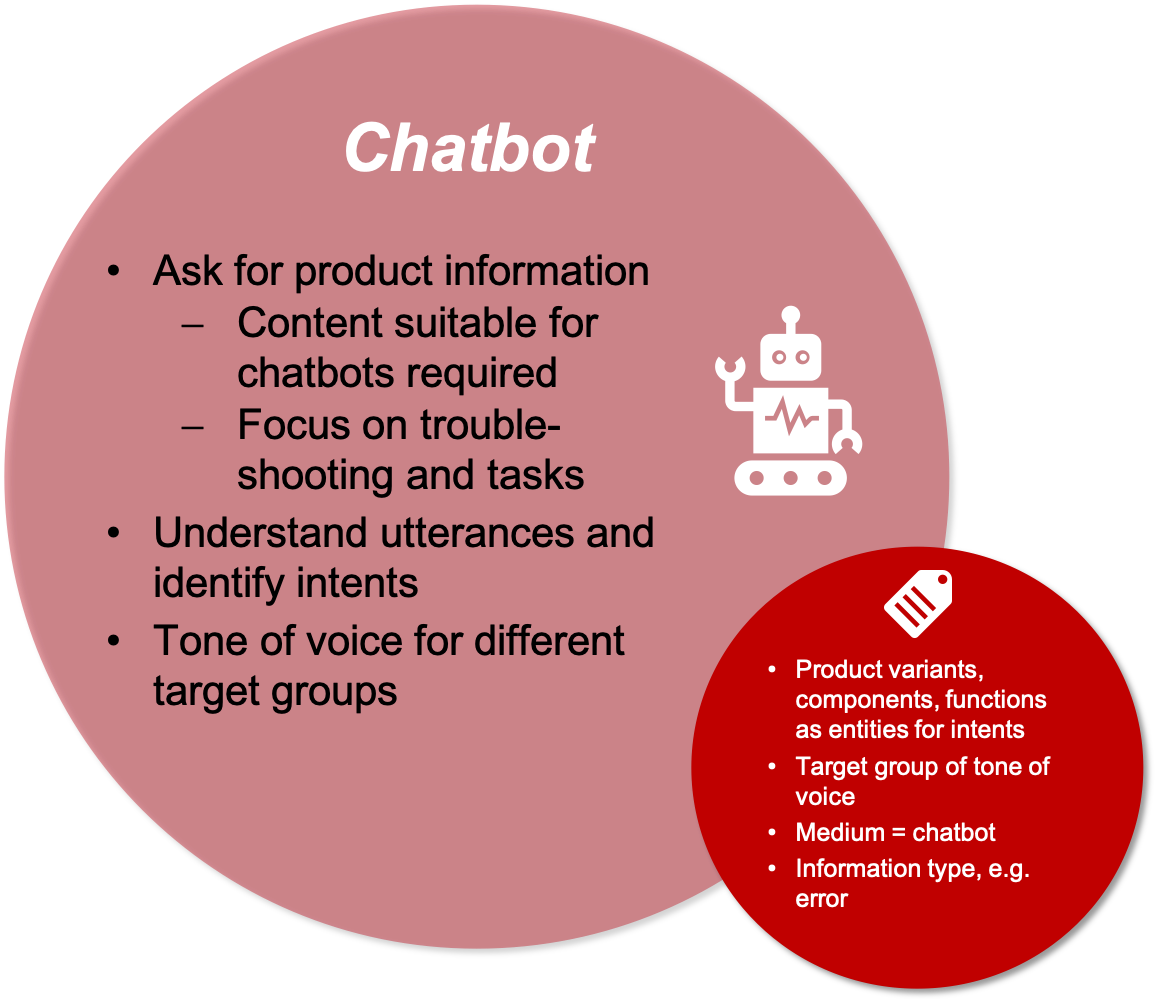
To find the right answers, chatbot implementations also need metadata. They must be able to recognize which product variant is involved, in which component or function a fault has occurred in and who is currently asking the question. The latter can be important when selecting the right tone of voice. It must also be clear what content needs to be delivered with the answer, e.g., whether it is more about a specific solution to a problem or general background information.
Scenario 2: digital twins
A digital twin is an electronic representation of all components, services, and interfaces of a technical system. A system can include components from several manufacturers. A digital twin also contains information from the technical documentation.
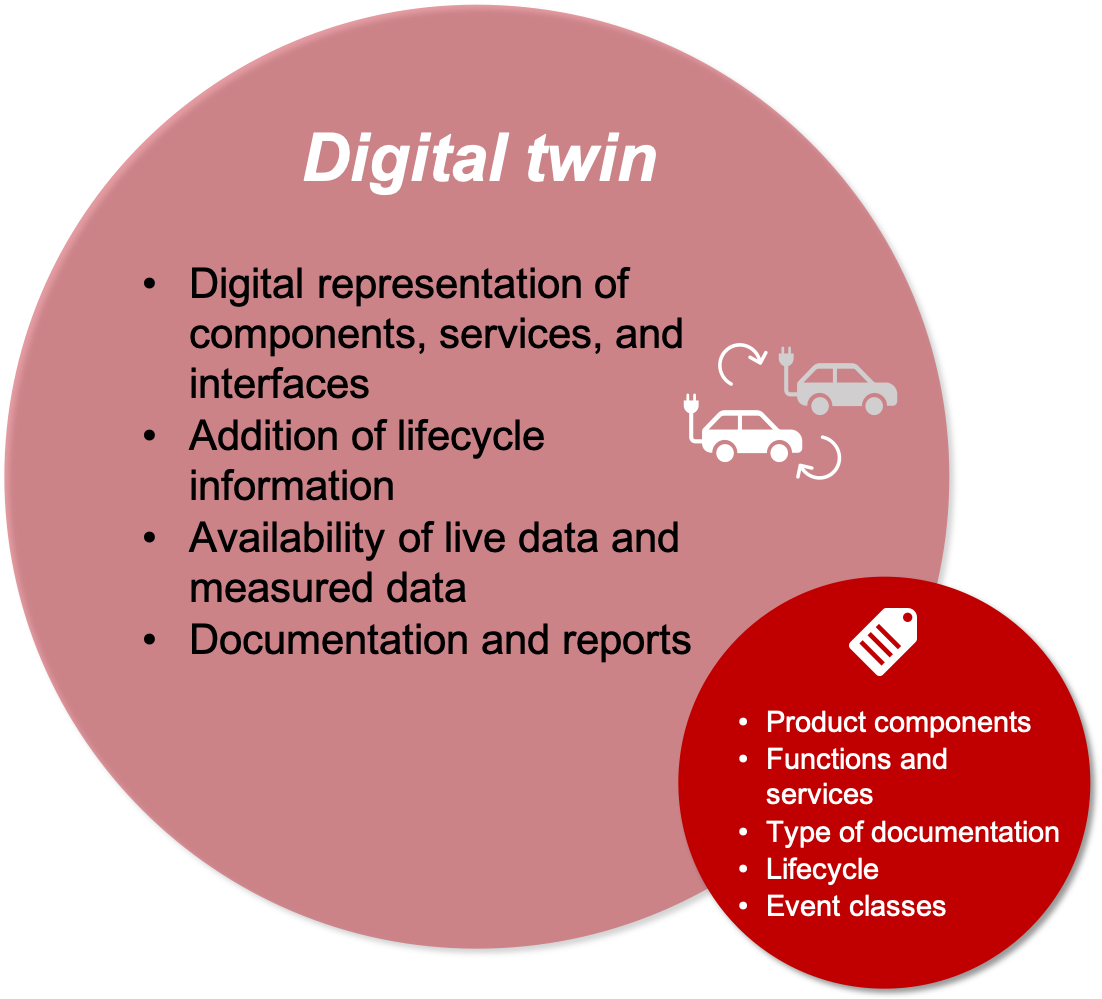
Further information is added during the lifetime of a technical system: parts are replaced, interfaces added, maintenance work carried out, and firmware updated. All this lifetime information is added to the digital twin.
If someone searches for information in a digital twin, they will also need metadata, for example, to search for specific components, to find the appropriate instructions for a fault, or to receive instructions for pending maintenance work.
Scenario 3: self-service portals
Self-service portals are becoming increasingly important for manufacturers. They let users, service technicians, and developers find help and information about a product, for example, instructions, solutions to problems, and technical data.
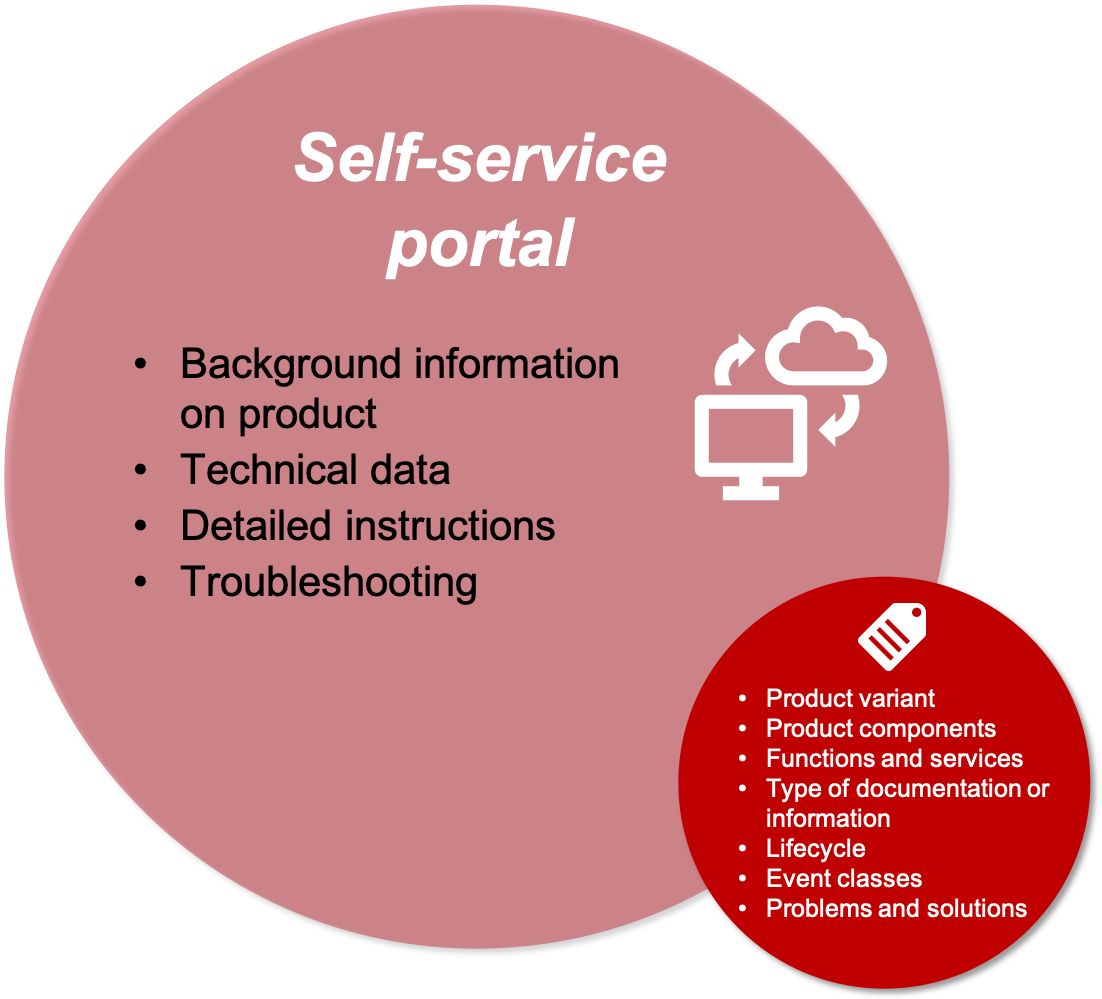
Metadata plays a particularly important role in a self-service portal, as information from different sources is usually pooled here. It is filtered by product variant, product function, and target group and searched for solutions to a problem. Similar metadata as in the previous scenarios is needed.
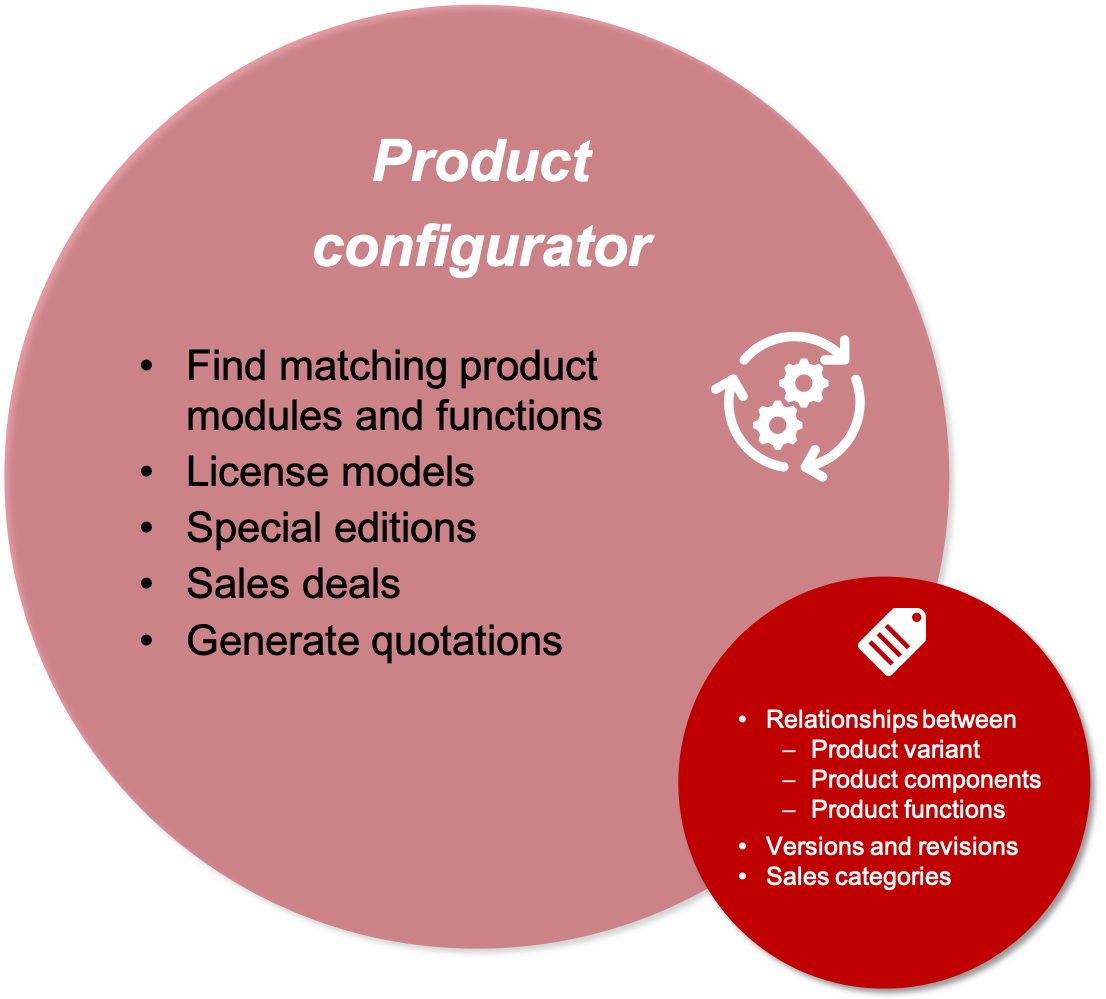
Scenario 4: product configurators
Many manufacturers offer product configurators. Customers use them to put together their desired product from certain modules and with specific functions and product features. Product configurators can be found in consumer products and in the industrial environment. Technical communication also plays a role here, as there must naturally also be customized documentation for the assembled products. Documents such as data sheets and functional descriptions can also help with a purchasing decision.
A product configurator also needs metadata, as it must know the relationships between components, modules, functions, features, ordering options, licenses, prices, and product variant. A link to appropriate documentation content may also need to be established.
Is all this metadata used in technical writing too?
There are many different use cases that require metadata. Some types of metadata such as product data, target group and information types appear in a number of the scenarios mentioned. What does this mean for technical writing? Does all this metadata also need to be located in the CCMS to deliver appropriate content for each of these scenarios? This raises the following questions:
- Does the technical communicator even know all the usage scenarios of their content and the metadata required? Does the technical communicator know which usage scenario involves which product features and which parameters describe the situation so that they can also prepare the right documentation for it?
- Who originally defines which metadata? Who is in charge of updating and synchronizing the metadata in the company?
- What happens when product characteristics and use cases change?
- Should the technical communicator assign all this metadata manually? In the chatbot scenario, which requires highly granular content, this might be necessary at a sentence level and would be very time-consuming.
- What happens if information for a new usage scenario needs to be published, e.g., because there is now a chatbot for the service? Should the technical communicators then subsequently annotate all existing content with additional metadata?
- Which metadata model can technical communicators use for the documentation and the products? Are there established standards that can be used as guidelines here? Are there vocabularies that can be adopted and expanded?
Creating a cross-application information model
The CCMS is not suitable for managing and maintaining all the metadata required. The administrative metadata for the technical documentation and the variant-generating characteristics are duly stored in the CCMS. But the CCMS is the wrong place for general product models, the digital twin and linked data models.
Also, the metadata needed for different application scenarios overlaps. All this leads to the conclusion that the right approach is to pull the metadata out of the individual applications, combine it and manage it in a cross-application information model.
iiRDS as a starting point
iiRDS can be used to map and manage metadata that is relevant for technical communication. iiRDS provides connecting points for other metadata and models, for example, for the digital twin of a machine with information on components, functions, and events. This means iiRDS can be used as a starting point or component of a larger information model.
When using a cross-application information model, the metadata no longer has to be defined and managed separately for the individual usage scenarios. Various types of metadata can be brought together in the information model, including product features, product functions, technical data, information types, target groups, etc.
Digital information twin
Based on the digital twin, we call this information model the digital information twin. To manage documentation processes for products with this type of information twin, the following information is important:
- Information from the product’s digital twin, including components, functions, and product features
- Metadata for technical documentation, e.g., topic types
- A generic information model for the contents of technical documentation
- Knowledge about the existing information units in the CCMS
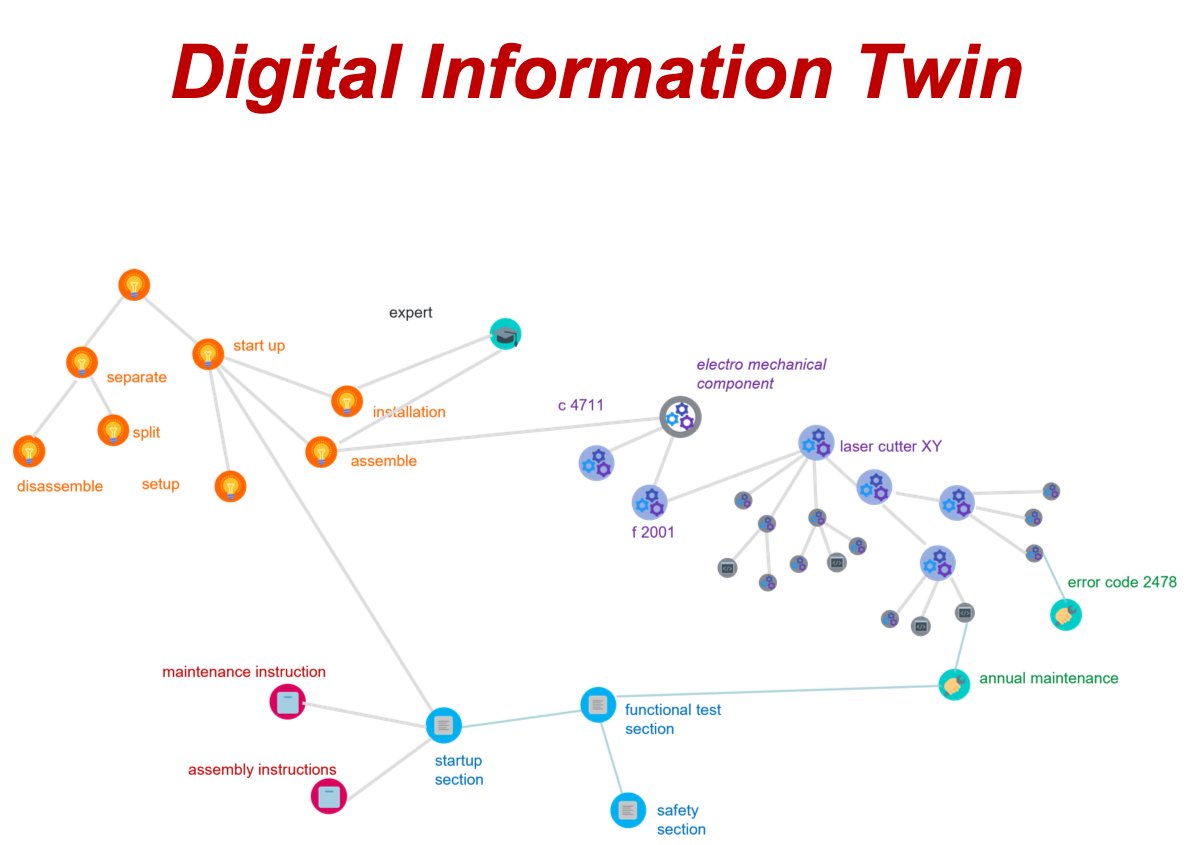
The digital twin shown here relates to an example machine, a laser cutter, consisting of various components. The product's parts list is usually used to model the components. The components and their equipment define the product features, product characteristics and functions. Actions such as maintenance, information such as maintenance intervals, and events such as errors relate to the components and functions. The different types of information in the twin are linked by relationships, e.g., an error message relates to a specific component and requires specific troubleshooting actions.
Therefore, the digital information twin is (just like the classic digital twin of assets) not simply a hierarchical tree (as we know it from metadata classifications), but a network of linked information.
Besides the product-related metadata, there is also the metadata of the technical communication to consider including:
- Information types for topics (e.g., instructions for action or troubleshooting descriptions) and documents (e.g., assembly instructions and maintenance instructions)
- Target group and role for which the information is relevant
- Product life cycle phase to which the information relates, e.g., maintenance and commissioning
- Safety relevance of the information
Another component of the digital information twin is a generic information model for the company's technical documentation. This describes which documentation content is needed for the company's products. If the products fall under the Machinery Directive, for example, then safety instructions and descriptions of the activities during operation and maintenance are mandatory. In addition, the manufacturer may want to list the technical data of the product in the documentation, as well as the documentation of the associated software product. The generic information model contains the necessary content and also stores information on what elements of this content already exist in the CCMS.
In interacting with the product model, it is therefore possible to derive from the digital information twin what content is needed for the documentation of a specific component or a specific product function and whether this content already exists. For example, if an author is appointed to document the functional test by a specialist member of staff for the laser cutter used in our example, they can use the digital information twin's network to determine the content for this documentation.
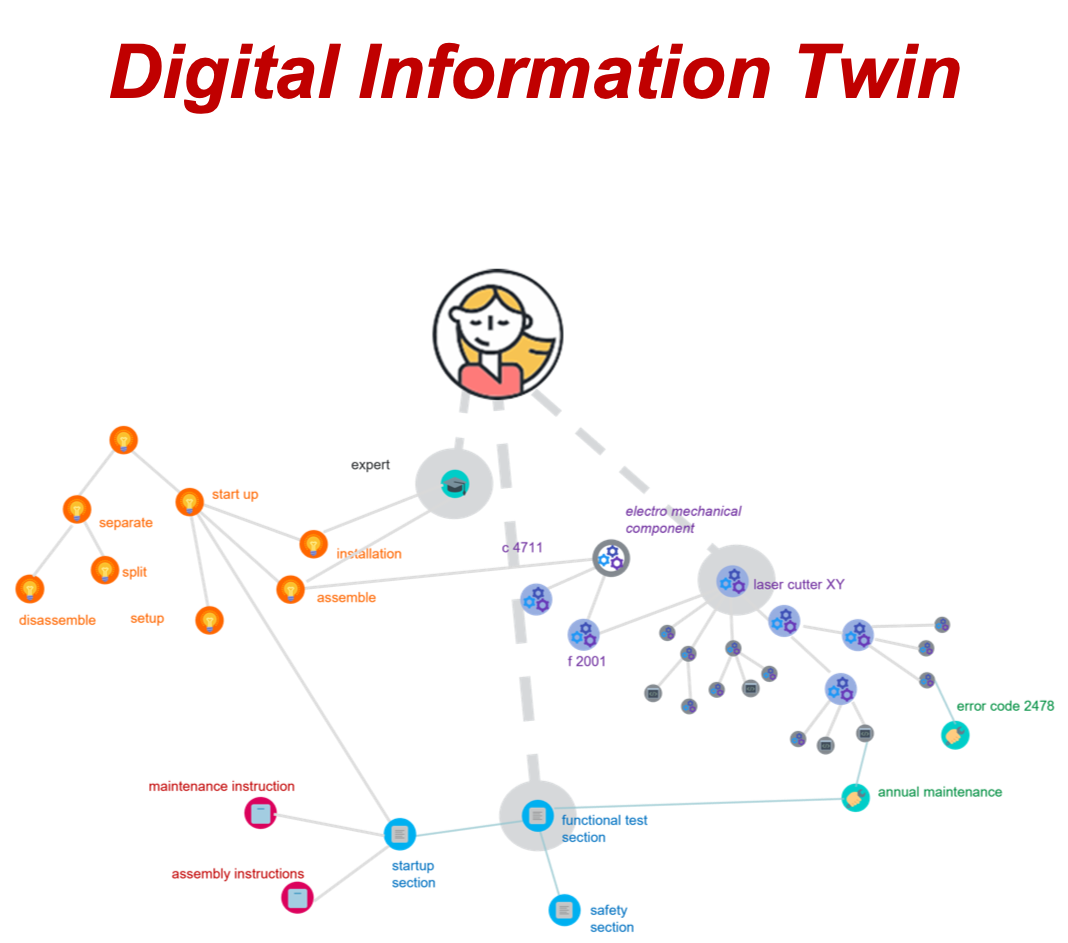
In component content management systems, this step of compiling content based on product configuration and content type often only takes place during publication, in the form of a publication configurator. With the digital information twin, this compilation takes place outside the CCMS and well before publication: when planning the content and initiating the documentation project.
This approach not only makes it possible to find existing content, but also to uncover gaps. For example, a technical communicator may want to describe a certain action for a product variant in a certain scenario and realizes that the action is recorded in the digital information twin, but there is no content for this scenario yet.
Defining a request for content
A digital information twin can be used to separate metadata management from the CCMS and to dynamically compile required content for a documentation project. This compilation can then be transmitted to the CCMS in the form of a “request for content” so that the technical communicators can create and edit the content there.
The following image shows an example request for content in the digital information twin’s interface. Content that already exist is marked.
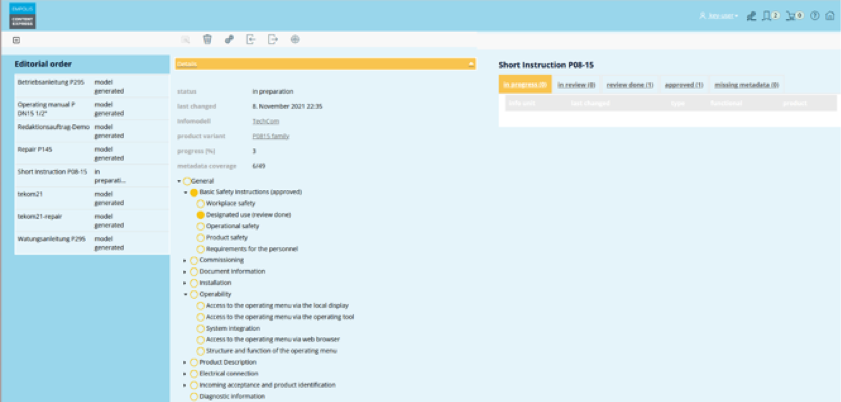
Both the existing content and the content to be created are already fully populated with the metadata they carry in the digital information twin, i.e., component, function, product life cycle, etc.
Creating and editing content
After the information units have been compiled, the request for content is transferred from the digital information twin to the CCMS, where it can be processed by the technical documentation team.
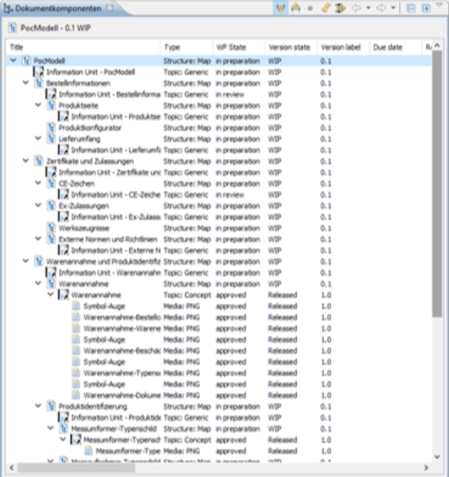
As the information units are already populated with metadata, technical communicators do not have to manage and assign this metadata in the CCMS. They can fully concentrate on their core tasks, such as technical writing, target group analysis, modularization, reuse, and terminology management.
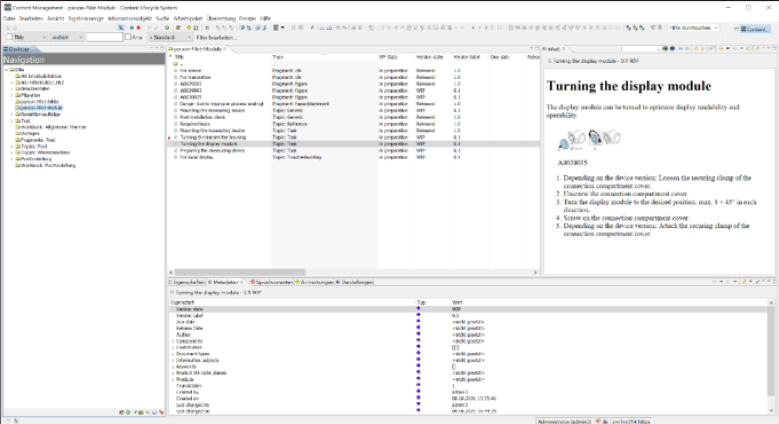
When the documentation tasks are finished, the content details are fed back into the digital information twin with the help of the request for content. The actual content stays in the CCMS, but the metadata is updated in the digital information twin. This also includes administrative metadata from the CCMS such as author or content and translation status. When a colleague creates the next editorial order, the updated content is listed there and can be reused.
New documentation processes
The outsourcing of metadata management from the CCMS is also leading to the emergence of new roles in technical communication:
- Information architecture including metadata modeling: building and maintaining the digital information twin, creating templates, content types and validation rules
- Project management: compiling and monitoring documentation projects and requests for content
The digital information twin turns the three-stage documentation process we presented at the beginning into a five-stage process that starts with the modeling of the metadata. The digital information twin needs to be updated before creating content. The digital information twin not only supplies the CCMS but can also be used for other usage scenarios such as a content delivery portal and a product configurator.
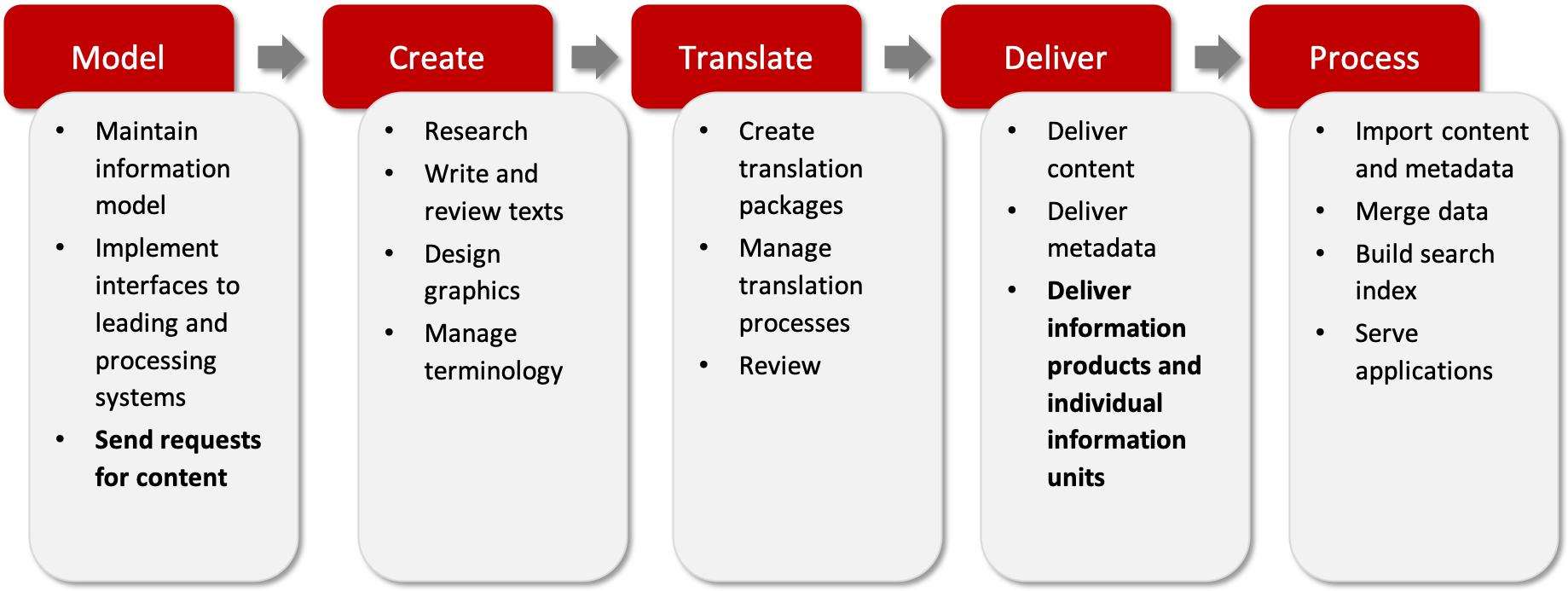
The digital information twin compiles the requests for content for the CCMS so that the familiar processes of creation, translation and delivery can be triggered.
For the delivery, the new process again differs from the traditional documentation process: Individual content modules (topics or information units) can now be delivered instead of complete documents, including their metadata. Content can therefore be continuously updated in the delivery channels, e.g., in a content delivery portal (continuous delivery).
The delivered content and related metadata are then processed further by the downstream systems. Further processing includes display on web pages, construction of a search index and merging of data from different sources.
Metadata models for smart technical documentation
parson creates a metadata model for your technical documentation!