API documentation – What software engineers can teach us
When asking software engineers about API documentation, you soon find out that there are two groups. The first group is convinced that good code does not require any explanation. Members of the second group frequently read documentation and even enjoy writing it. You also find out that software engineers have completely different opinions and approaches when it comes to the layout, presentation, and contents of a perfect API documentation.
For two years, our small team of technical communicators at Merseburg University of applied science has been looking into the question on how to improve API documentation. We conducted intensive research on the contents and structure of good API documentation, but also on the target group itself – the software engineers.
Research was conducted using interviews, questionnaire surveys, and a series of observations, which made it possible to directly observe how software engineers solve their programming tasks. We also looked at existing studies in the field of developer documentation. As a result of our studies, we can now draw a rather accurate picture what software engineers require from good API documentation and make suggestions on how to improve it.
Software engineers are different
We know that software engineers have different programming experience and work in different system environments. With the help of our interviews, the questionnaire, and the observation series, we also identified two fundamentally different work methods. These differences have a special impact on the reading behavior of software engineers and need to be considered when creating API documentation.
Some software engineers intuitively begin to familiarize themselves with a new API and start working from an example. They prefer to immediately dive into the matter. They get to know the API bottom-up, based on the code. Other engineers find it useful to first understand the API as a whole. Before they start working, they read conceptual information and get into the matter top-down. These different patterns became especially obvious during our series of observation (see image 1). Out of 11 test persons, six viewed and partly read the conceptual information of the tested manufacturer documentation. Five ignored the concept part.
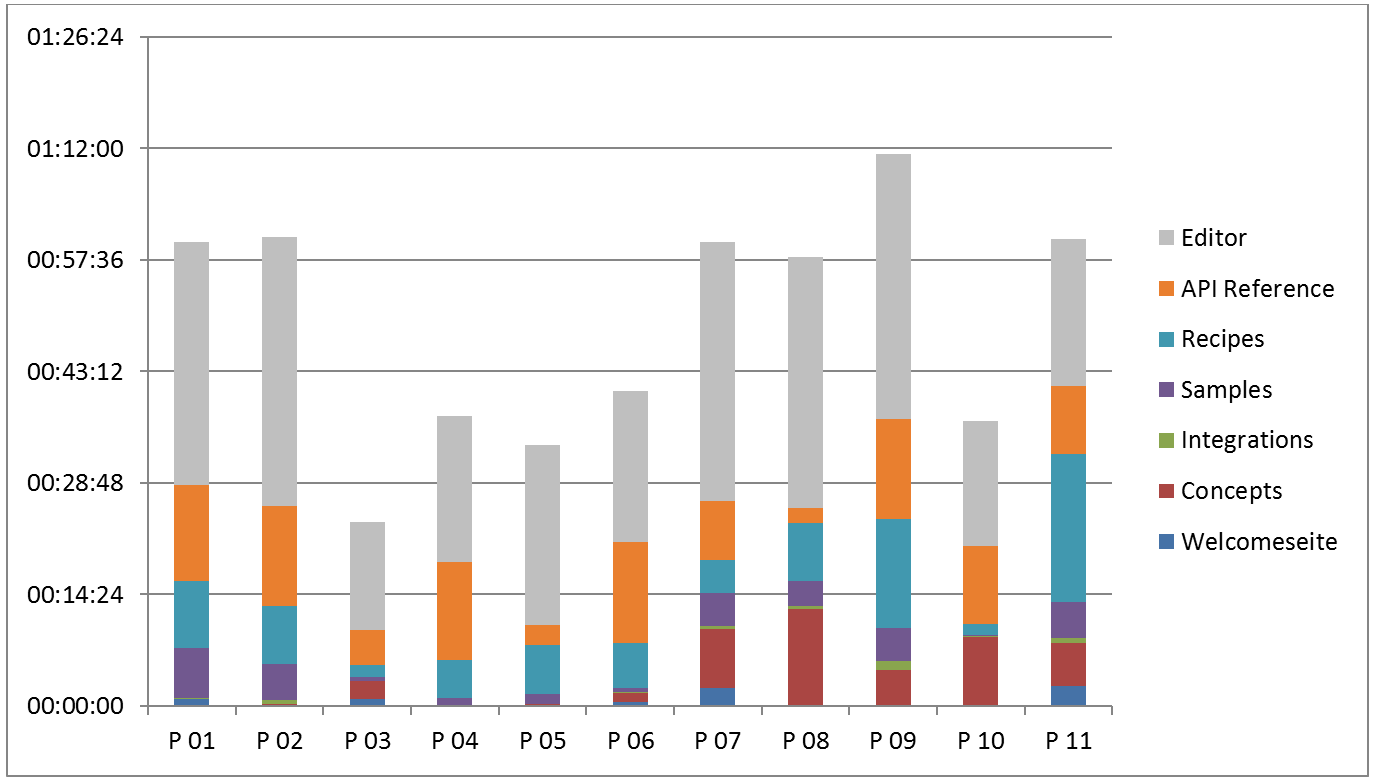
Analyzing eye-tracking records, we found that software engineers often did not read pages line by line but rather scanned a page. Visual elements, such as hyperlinks, example code, and the navigation bar, caught their special attention. But they would only actually start reading if the sample code did not solve their problem. This behavior was also influenced by how the software engineers rated the difficulty of a task. If they found a task hard to solve, they were more inclined to read.
Content structure
Looking at the different work methods and the reading behavior of software engineers, it quickly becomes obvious that the design and structure of API documentation is important. In the questionnaire, one of the most mentioned shortcomings in documentation was lack of clarity. That was rated far worse than other shortcomings, such as complicated document structures (see image 2). Today, many manufacturers use different document types to reduce this complexity: getting-started documents, developer guides, references, concepts, and examples. But this classification is not always helpful.
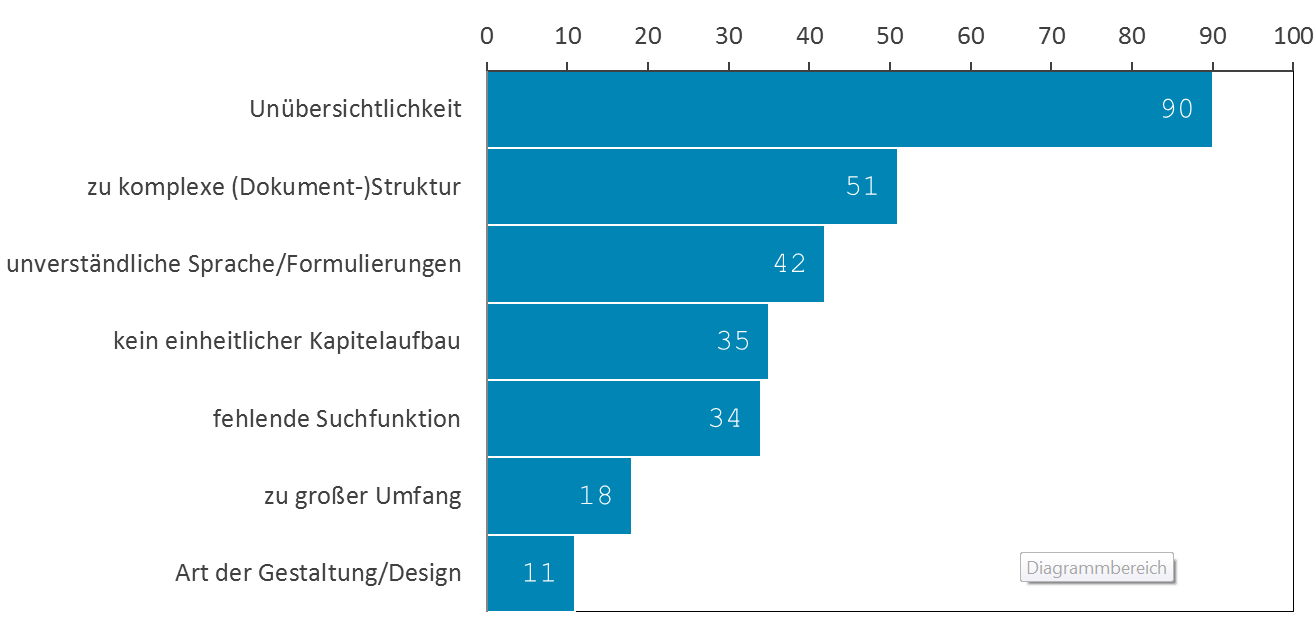
*See translation of values at the end of the document.
In our series of observation, we found that software engineers could not clearly determine which document type would hold the answer to their question. What’s the difference between a getting-started document, a tutorial, and a recipe? Technical writers are familiar with the classification of different types of text and information; software engineers are not.
For software engineers, it is less important that information is bundled into small portions. They look for answers. They want to quickly find solutions. If they need to decide whether to find the answer in a getting-started document, a reference, or in a tutorial, they are slowed down and not helped sufficiently.
The observation series also showed that software engineers avoided documents with titles they could not clearly interpret. For example, in our study, they ignored the “recipe” document, even though the information they were looking for was in it.
In larger API documentation projects, we still need to cluster information. We may otherwise not find anything. Clustering information by content makes sense, considering that software engineers always want to solve a particular problem with the API. Take a parcel delivery API, for example. To structure it with a getting-started document, concept, or reference would make little sense. The focus should instead be on parcel delivery. This makes it possible to organize the API by service providers, shipments, addresses, and services.
We still need a general overview of and easy access to the API. Whoever decides whether or not to use an API needs to see at first glance what it offers, how it works, and how it integrates. This information should be placed at the same level as the content clusters, for example, as an overview. The title needs to be descriptive so that the reader immediately knows what to expect. This is also important for the integration of the API. Many software engineers told us in interviews and questionnaires that the first steps in an API were the hardest. After this was done, they did not need much documentation. That means that the information on how to integrate the API should also be bundled and made available, similar to a getting-started document.
Navigation is elementary
Inconsistent navigation makes it often even harder to structure API documentation. We frequently found navigation bars in API documentation that disappeared while scrolling, tables of contents at the beginning of chapters, or navigation structures that did not contain all chapter levels. After a few clicks we landed in no-man’s land and could only return to our starting point with the browser buttons.
Like in website design we have to consider different criteria for the navigation in API documentation. Breadcrumb menus and foldable navigation bars are useful. Also, the navigation should always be visible so that readers know where exactly they are in the overall structure.
Currently, much of API documentation lacks this kind of transparency. The navigation structure is often too varied. Readers are overwhelmed by the sheer number of possibilities. We need to find a balance between a stern, single-track navigation, which may patronize software engineers, and more diverse approaches that offer, for example, graphical menus for presetting the language, document type or version – but can also quickly cause confusion, despite their inherent flexibility.
Domain knowledge is essential
Results from other research as well as from our interviews also confirmed the findings in our series of observation. Software engineers with background knowledge about the test API could solve tasks much more quickly than those with similar programming experience but without the domain knowledge. The test API in our observation series came from the e-commerce sector. Software engineers who had worked in this field had almost no difficulty using it (see image 1: test persons 3, 4, 5, 6, and 10 came from the e-commerce sector).
That means that building up domain knowledge seems to play an important role for learning a new API. But where do we place this knowledge if we want to avoid a structure by text type and thus skip the “concept” part? Considering the way software engineers work and read, we need to place background knowledge and other important information exactly where they will look.
Based on the results from our interviews, questionnaires, and observation series, only code examples can serve this purpose. Software engineers usually like sample code. In our series of observations, all test persons looked at the samples and used them as a starting point for their own coding. If we disguise important information as code comments and make them visually stand out from other sample code, we can be sure that this content will be seen and also read (see image 4). That does not mean, however, that we should neglect detailed descriptions. They are still read by software developers who are interested in the concepts.

This specific proposal and above mentioned results present only a small part of our previously conducted research. Our research project is still ongoing. We are interested in a larger number of test persons and encourage companies to participate.
The results derive from a joint research project with Professor Dr. Michael Meng and Andreas Schubert (MA).
* Values in image 2 (top to bottom): complexity, too complex (document) structure, incomprehensible language and phrasing, inconsistent chapter organization, missing search functions, too large, type of layout/design.
Translation by Uta Lange, parson AG
You may also like our knowledge article Documentation for Software Engineers.