RDF is not XML – RDF Serialization and iiRDS Metadata
Zugehörige Leistung: Metadatenmodelle für die Technische Dokumentation
Now that everyone is talking about metadata, it's only natural from a technical writer's point of view to look for an XML-based solution. How can I add metadata to my XML content? Established standards like DITA provide XML elements and structural concepts to enrich content with metadata. The following snippet shows metadata in a DITA topic. <prodinfo> <prodname>CremaE61</prodname> <component>Lever</component> </prodinfo>
While this is fine for authoring, the exchange and delivery of documentation in an Industry 4.0 context requires a more sophisticated metadata concept. For us humans the above snippet is easy to read. There's a product “CremaE61” with a component “Lever”. But a machine does not have such implicit knowledge about the semantics of these XML elements. A smart application could probably process the semantic DITA elements in a meaningful way. For example, generate a navigation structure that reflects the component tree of the product. But the application would have to query each content file and collect all topics that have a prodname element with a CremaE61 text node.
This approach is limited. Implementing semantic processing with conventional tools is costly and doesn't scale well. And it cannot easily process metadata that is not in the content. For example, displaying a list of out-of-stock parts for next scheduled maintenance. Adding additional metadata and information is easy with semantic web technologies, though. And that's why the new tekom standard for intelligent information request and delivery iiRDS uses RDF.
The resource description framework RDF models metadata as triples of subject-predicate-object. For example, the triple CremaE61-hasPart-Lever expresses the statement that the lever is a component of CremaE61. One object can be the subject of the next triple: The lever, for example, can consist of individual parts, which is expressed by additional statements like Lever-hasPart-Screw42. In this way, multiple triples are created that form a web of knowledge graphs. To extend the existing metadata, new triples reference existing subjects which then become the new objects. A machine can process the limited RDF vocabulary and all vocabularies that are RDF-based as every statement can be reduced to a triple pattern.
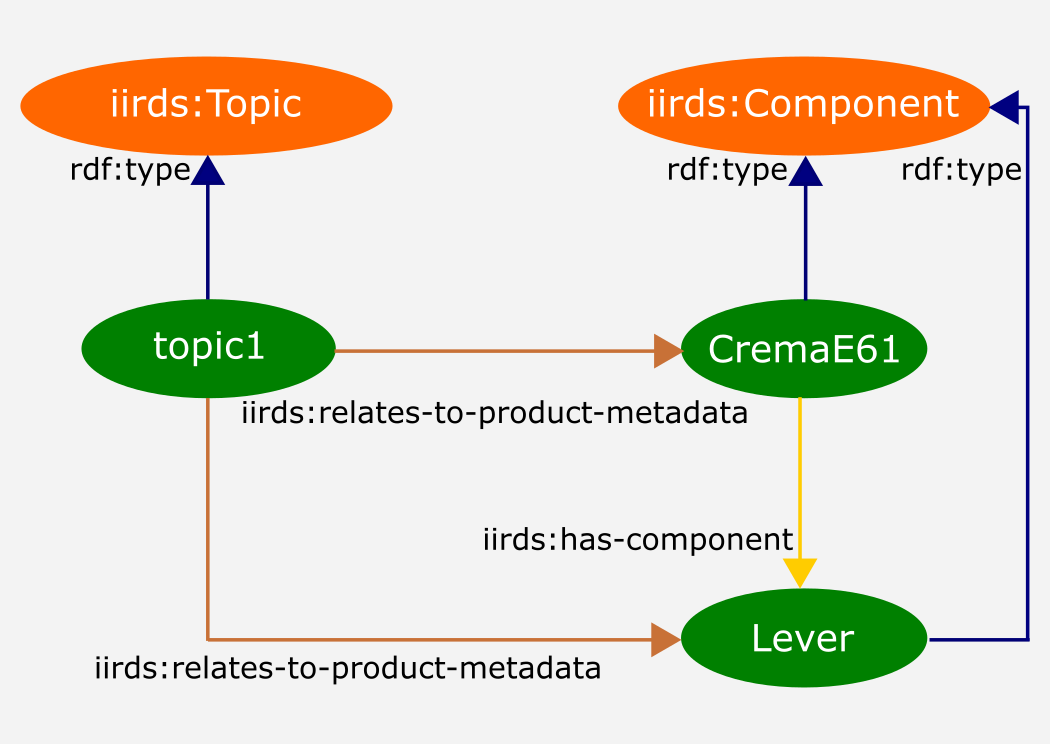
But integrating metadata and extending the knowledge graph requires a good understanding of the underlying semantic model. In this article, I'd like to focus on the basics. So, let's have a look at some triples. If we model the above DITA snippet in iiRDS, we may get the following representation: <iirds:Topic rdf:about="http://myCompany.it/myRelease#topic1"> <iirds:relates-to-product-metadata> <iirds:Component rdf:about="http://myCompany.it/myProduct#CremaE61"> <iirds:has-component rdf:resource="http://myCompany.it/myProduct#Lever"/> </iirds:Component> </iirds:relates-to-product-metadata> <iirds:relates-to-product-metadata> <iirds:Component rdf:about="http://myCompany.it/myProduct#Lever"/> </iirds:relates-to-product-metadata> </iirds:Topic>
But that's also XML. That's easy peasy, isn't it? Unfortunately, it's a bit more complicated. The above RDF snippet is only one possible example. There are multiple ways of writing the same set of triples in RDF/XML. Here's another one: <rdf:Description rdf:about="http://myCompany.it/myRelease#topic1"> <rdf:type rdf:resource="http://iirds.tekom.de/iirds#Topic"/> <iirds:relates-to-product-metadata rdf:resource="http://myCompany.it/myProduct#CremaE61"/> <iirds:relates-to-product-metadata rdf:resource="http://myCompany.it/myProduct#Lever"/> </rdf:Description> <rdf:Description rdf:about="http://myCompany.it/myProduct#CremaE61"> <rdf:type rdf:resource="http://iirds.tekom.de/iirds#Component"/> <iirds:has-component rdf:resource="http://myCompany.it/myProduct#Lever"/> </rdf:Description> <rdf:Description rdf:about="http://myCompany.it/myProduct#Lever"> <rdf:type rdf:resource="http://iirds.tekom.de/iirds#Component"/> </rdf:Description>
We could even leave out some of the explicitly modeled information if we extend the knowledge graphs and take the definition of iirds:has-component into account. Then the RDF/XML snippet looks as follows: <rdf:Description rdf:about="http://myCompany.it/myRelease#topic1"> <rdf:type rdf:resource="http://iirds.tekom.de/iirds#Topic"/> <iirds:relates-to-product-metadata rdf:resource="http://myCompany.it/myProduct#CremaE61"/> <iirds:relates-to-product-metadata rdf:resource="http://myCompany.it/myProduct#Lever"/> </rdf:Description> <rdf:Description rdf:about="http://myCompany.it/myProduct#CremaE61"> <iirds:has-component rdf:resource="http://myCompany.it/myProduct#Lever"/> </rdf:Description> <rdf:Property rdf:about="http://iirds.tekom.de/iirds#has-component"> <rdfs:domain rdf:resource="http://iirds.tekom.de/iirds#Component"/> <rdfs:range rdf:resource="http://iirds.tekom.de/iirds#Component"/> </rdf:Property>
The definition of domain and range of iirds:has-component states that the property points from an iirds:Component to another iirds:Component. So, the RDF/XML can omit the triples CremaE61-type-Component and Lever-type-Component. Domain and range allow to infer these triples. The triple CremaE61-has-component-Lever alone is sufficient.
How do I query those knowledge graphs with XSLT? It looks awfully unpredictable! The answer is simple, don't try it! You might be able to process parts of the knowledge graph but even the mightiest XSLT and XPATH skills are going to leave you stranded in a world of pain. RDF is not meant to standardize a document structure with a hierarchy of XML elements. It provides an abstract vocabulary to form statements about resources as knowledge graphs.
To make things worse, there's more to RDF than just different RDF/XML renderings. RDF/XML is only one serialization of RDF. Other RDF serializations are turtle with its subset N-Triples and N-Quads, and JSON-LD. The following example shows the triples in JSON-LD. { "@id" : "http://myCompany.it/myRelease#topic1", "@type" : "iirds:Topic", "relates-to-product-metadata" : [ "http://myCompany.it/myProduct#CremaE61", "http://myCompany.it/myProduct#Lever" ] }, { "@id" : "http://myCompany.it/myProduct#CremaE61", "@type" : "iirds:Component", "has-component" : "http://myCompany.it/myProduct#Lever" }, { "@id" : "http://myCompany.it/myProduct#Lever", "@type" : "iirds:Component" }
So, what? Is all lost then? No! Thankfully, there's a couple of frameworks available to process and query knowledge graphs no matter what serialization. A widely used Java framework is Apache Jena, for example. Google your favorite programming language and RDF and you're likely to find mature libraries that help processing semantic triples. There's certainly a learning curve for everyone new to semantic technologies but it’s an established and widely used technology with a broad and helpful community. Just get out of your XML comfort zone and keep in mind: RDF is not always XML and not all RDF/XML is the same!
Good reads:
- Berners-Lee, Tim Berners-Lee: Why RDF model is different from the XML model, 1998 https://www.w3.org/DesignIssues/RDF-XML.html
- Cambridge Semantics: RDF vs. XML, https://www.cambridgesemantics.com/blog/semantic-university/learn-rdf/rdf-vs-xml/
- W3C: XML to RDF Transformation processes using XSLT, https://www.w3.org/community/rax/wiki/XML_to_RDF_Transformation_processes_using_XSL
Thanks to Martin Kreutzer (Empolis) for his helpful feedback.