API-Dokumentation – Was wir von Entwicklern lernen können
Befragt man Entwickler nach API-Dokumentation, tun sich ziemlich schnell zwei unterschiedliche Lager auf. Es gibt Entwickler, die davon überzeugt sind, dass guter Code überhaupt keiner Erklärung bedarf, und natürlich auf der anderen Seite auch jene Entwickler, die häufig Dokumentation lesen und sie auch selbst gern schreiben. Ebenfalls verschiedenste Meinungen und Ansätze existieren bezüglich Aussehen, Darreichung und Inhalt einer perfekten API-Dokumentation.
An der Hochschule Merseburg forscht seit zwei Jahren ein kleines Team aus Technischen Redakteuren an der Optimierung von API-Dokumentation. Fragen nach den Inhalten und dem Aufbau einer guten API-Dokumentation werden dabei genauso intensiv untersucht wie die Zielgruppe – die Softwareentwickler – selbst.
Mithilfe von Interviews, einer Fragebogenuntersuchung und einer Beobachtungsreihe, bei der direkt verfolgt wurde, wie Entwickler Programmieraufgaben lösen, hat sich inzwischen, auch im Hinblick auf bereits bestehende Studien im Bereich der Entwicklerdokumentation, ein ziemlich genaues Bild ergeben zu den Anforderungen von Entwicklern an gute API-Dokumentation. Aus diesen Anforderungen lassen sich Optimierungsvorschläge ableiten.
Entwickler: Verschieden
Entwickler unterscheiden sich natürlich in ihrer Programmiererfahrung und hinsichtlich der Systemwelt, in der sie zu Hause sind. Mithilfe unserer Interviews, des Fragebogens und der Beobachtungsreihe konnten wir darüber hinaus auch zwei ganz verschiedene Arbeitsweisen der Entwickler identifizieren. Gerade dieser Unterschied, der sich vor allem auf das Leseverhalten auswirkt, muss bei der Erstellung von API-Dokumentation berücksichtigt werden.
Es gibt Entwickler, die sich eher intuitiv in eine neue API einarbeiten und ausgehend von einem Beispiel starten. Sie steigen bevorzugt direkt ein und erarbeiten sich den Umfang der API ausgehend vom Code von unten nach oben. Auf der anderen Seite gibt es Entwickler, die es nützlich finden, die API in Gänze zu verstehen. Sie lesen vor dem Start zunächst konzeptionelle Informationen und erarbeiten sich die Inhalte eher von oben nach unten. Diese Verhaltensmuster wurden vor allem in der von uns durchgeführten Beobachtungsreihe sichtbar (vgl. Abbidlung 1). Von den 11 beobachteten Probanden haben nur 6 die konzeptionellen Informationen der getesteten Herstellerdokumentation angesehen und teilweise gelesen. Die anderen 5 Entwickler haben keinen Blick in den Teil „Concepts“ geworfen.
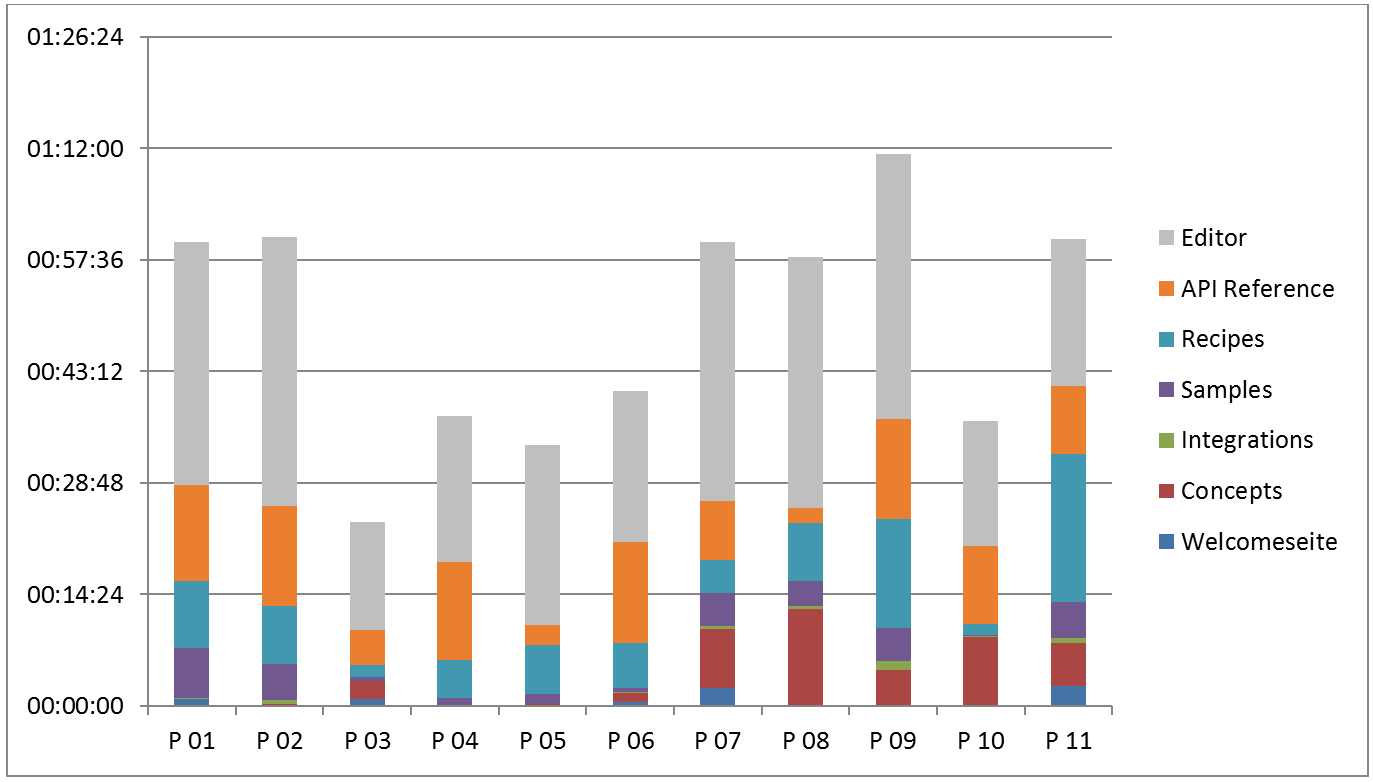
Generell lasen die Entwickler die Inhalte einer Seite oftmals nicht nacheinander, sondern scannten nur über die Seite, wie die Analyse der entstandenen Eyetracking-Aufnahmen ergab. Besondere Aufmerksamkeit bekamen dabei die visuell hervorgehobenen Elemente wie Hyperlinks, Beispielcode und die Navigation. Tatsächlich gelesen wurde meist nur, wenn aus dem Beispielcode keine Problemlösung abzuleiten war. Dieses Verhalten wurde auch beeinflusst von der individuellen Einschätzung des Schwierigkeitsgrades der Aufgabe. Empfanden die Entwickler die Aufgabe als schwer lösbar, waren sie eher geneigt zu lesen als bei Aufgaben, die ihnen leichter erschienen.
Struktur: Inhaltlich
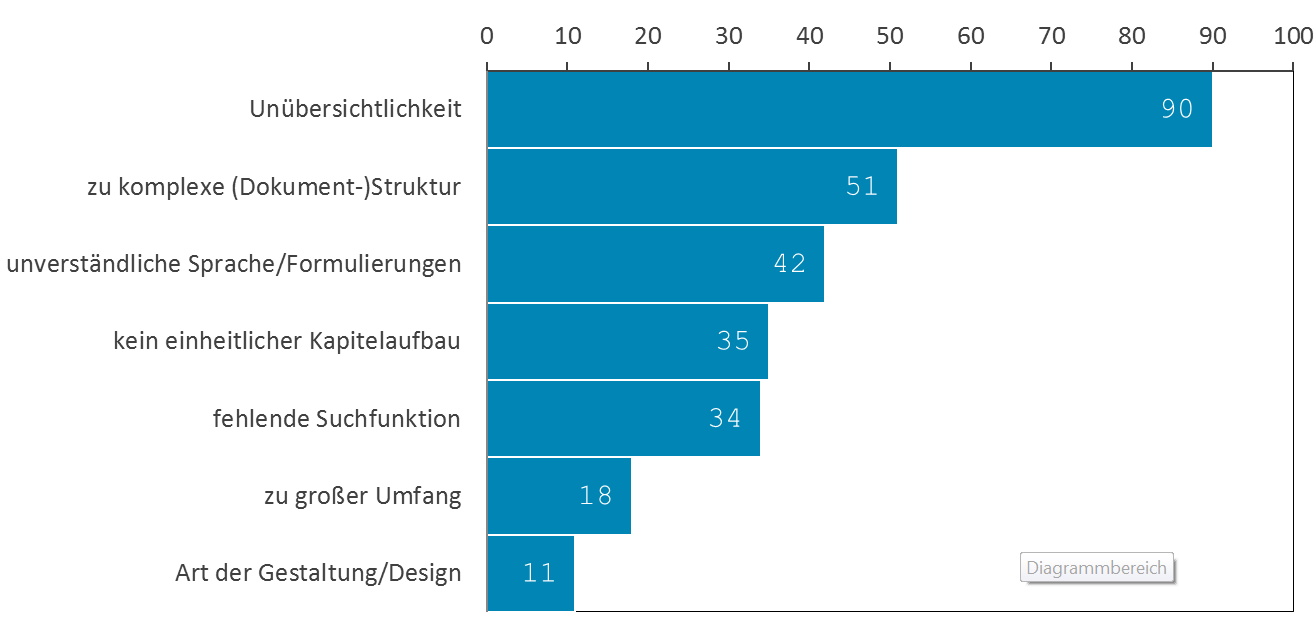
Im Hinblick auf die Arbeitsweisen und das Leseverhalten der Entwickler wird schnell klar, dass dem Aufbau und der Struktur einer API-Dokumentation große Bedeutung zukommt. Die Unübersichtlichkeit wurde auch im Fragebogen als häufigster Mangel weit vor anderen Mängeln, wie beispielsweise einer zu komplexen Dokumentstruktur, benannt (vgl. Abbildung 2). Um die Komplexität etwas zu mindern, hat sich heute zu weiten Teilen eine Bündelung nach Dokumenttypen durchgesetzt. Man findet die Getting Started-Dokumente, Developer Guides, Referenzen, Konzepte und Beispiele. Doch ist diese Klassifizierung nicht immer hilfreich.
In unserer Beobachtungsreihe wurde offensichtlich, dass die Entwickler nicht eindeutig zuordnen konnten, in welchem Dokumenttyp ihre persönliche Fragestellung beantwortet wird. Worin liegt der Unterschied zwischen einem Getting Started, einem Tutorial oder Rezept? Wir als Technische Redakteure können die feinen Nuancen unterscheiden, doch stammen die Entwickler nicht aus unserer Welt der Klassifizierung von Textsorten und Informationsarten.
Für Entwickler ist es weniger entscheidend, dass die Informationen in kleine Säcke zusammen geschnürt und damit vermeintlich übersichtlich präsentiert werden. Sie sind allein auf der Suche nach Antworten zu ihren Fragen. Sie möchten möglichst schnell zum Ziel gelangen. Die Frage danach, ob die gesuchten Inhalte in ein Getting Started, die Referenz oder doch in ein Tutorial oder gar Konzept sortiert wurden, hält auf und ist bei der Suche nach Lösungen oft nicht hilfreich.
Auch hat die Beobachtungsreihe gezeigt, dass Bereiche, deren Titel die Entwickler nicht klar interpretieren konnten, im Fall unserer Studie z. B. der Begriff „Recipe“, komplett gemieden wurden, obwohl genau dort die gesuchte Information zu finden war.
Allerdings müssen gerade bei größeren API-Dokumentationen die Informationen geclustert werden, da sonst höchstwahrscheinlich überhaupt nichts mehr gefunden werden kann. Ausgehend davon, dass Entwickler immer auch ein spezifisches Problem mit der API lösen wollen, ist eine inhaltliche Strukturierung sinnvoll. Nehmen wir beispielsweise eine Paketversand-API. Hier wäre es sinnvoll, nicht nach Getting Started, Konzept oder Referenz zu untergliedern, sondern vielmehr das Liefern von Paketen selbst zum Mittelpunkt des Geschehens zu machen. So könnte die API nach Dienstleistern, Sendungen, Adressen und Services sortiert werden.
Die Möglichkeiten sich einen globalen Überblick zu verschaffen und einen leichten Einstieg zu unterstützen, dürfen natürlich dennoch nicht fehlen. So müssen beispielsweise die Entscheider für oder gegen eine API sehen können, was die API kann und bietet, wie sie arbeitet und integriert wird. Diese Informationen müssten der inhaltlichen Gliederung auf gleicher Ebene vorangestellt werden, beispielsweise als Überblick. Doch auch hier lohnt sich ein sprechender Name als Titel, der anzeigt, was in diesem Überblick tatsächlich zu erwarten ist. Dies gilt ebenfalls für die Integration der API. Viele Entwickler in Interview und Fragebogen nannten vor allem die ersten Schritte in einer API als die schwierigsten. Wenn es erst einmal „läuft“, kommen die Entwickler auch ohne viel Dokumentation zurecht. Demnach sollten auch diese Informationen gebündelt, ähnlich eines Getting Started zur Verfügung stehen.
Navigation: Elementar
Die Schwierigkeiten, API-Dokumentationen zu strukturieren, werden oftmals durch eine inkonsistente Navigation weiter verschärft. Nicht selten fanden wir bei aktuellen API-Dokumentationen Navigationsleisten, die beim Scrollen des Inhalts verschwanden, vorangestellte Inhaltsverzeichnisse oder aber Navigationsstrukturen, die nicht alle Kapitelebenen abbilden. Nach wenigen Klicks befanden wir uns im Niemandsland und kamen nur noch mithilfe der Browserschaltflächen zurück zum Ausgangspunkt.
Wie bei der Webgestaltung gilt es auch bei der Navigation für eine API-Dokumentation verschiedene Kriterien zu beachten. Breadcrumb-Menüs können gute Dienste leisten, genau wie Navigationsleisten, die sich ein- und ausklappen lassen, angelehnt an das Strukturbaum-Prinzip von klassischen Online-Hilfen. Des Weiteren sollte die Navigation stets sichtbar sein, sodass der Leser immer weiß, an welcher Stelle er sich in der Gesamtstruktur befindet.
Diese Transparenz fehlt vielen aktuellen API-Dokumentationen. Oftmals sind auch die Wege der Navigation zu vielfältig, sodass der Leser schon durch die schiere Anzahl der Möglichkeiten überfordert ist. Es gilt also eine Balance zu finden zwischen strenger einspuriger Führung, von der Entwickler sich vielleicht bevormundet fühlen, und multiplen Ansätzen mit z. B. grafischen Menüs zur Vorauswahl der Sprachen, Dokumenttypen, Versionen usw., die bei aller innewohnenden Flexibilität auch sehr schnell für Verwirrung sorgen können.
Domainwissen: Unverzichtbar
Was bereits andere Studien und ebenso unsere Interviews als Ergebnis hervorbrachten, bestätigte auch unsere Beobachtungsreihe eindrucksvoll. Die Entwickler, die bereits Hintergrundwissen zur verwendeten Test-API hatten, konnten die gestellten Aufgaben viel schneller lösen als Entwickler mit ähnlich langer Programmiererfahrung aber ohne die entsprechende Sachkenntnis. Die Test-API der Beobachtungsreihe stammte aus dem e-Commerce-Umfeld und konnte nahezu problemlos von den Entwicklern bewältigt werden, die selbst im Bereich e-Commerce tätig waren (vgl. Abbildung 1 – die Probanden 03, 04, 05, 06 und 10 stammten aus dem e-Commerce-Umfeld).
Somit kommt der Vermittlung von Domainwissen offenbar eine entscheidende Rolle bei der schnellen Einarbeitung in eine neue API zu. Doch wo muss dieses Wissen platziert werden, wenn wir doch Abstand nehmen von einer Gliederung nach Textsorten und damit verzichten auf einen Teil „Konzept“? Mit dem Blick auf die Arbeitsweisen und das Leseverhalten der Entwickler müssen Hintergrundinformationen und andere wichtige Informationen genau dort platziert werden, wo alle Entwickler einen Blick drauf werfen.
Im Hinblick auf die Ergebnisse von Interview, Fragebogen und Beobachtung können nur Codebeispiele diese Aufgabe erfüllen. Beispielcode wird generell von allen Entwicklern positiv bewertet und wurde auch in der Beobachtungsreihe von allen Probanden angesehen und als Ausgangspunkt für die eigene Programmierung verwendet. „Verkleidet“ man also die wichtigen Informationen als Codekommentare und hebt diese optisch vom restlichen Beispielcode ab, ist sicher, dass diese Inhalte gesehen und auch gelesen werden (vgl. Abbildung 4).
Trotzdem sollten natürlich auch immer ausführlichere Beschreibungen vorhanden sein, um die eher konzeptorientierten Entwickler ebenfalls zu berücksichtigen.

Dieser konkrete Vorschlag und die zuvor genannten Erkenntnisse sind natürlich nur ein kleiner Teil der bereits vergangenen Forschung. Im Moment dauern die Untersuchungen noch an. Wir sind daher immer interessiert an Firmen, die sich an Studien beteiligen möchten und damit die Anzahl möglicher Probanden weiter vergrößern.Lesen Sie auch zum Thema den Wissensartikel Documentation for Software Engineers.
Die Ergebnisse stammen aus der gemeinsamen Forschungsarbeit mit Prof. Dr. Michael Meng und Andreas Schubert (MA).